Data Structures of Unix File I/O
This blog post describes the basic data structures involved in file I/O on Unix and Linux. We’ll go through file descriptors, open file descriptions and file buffers, and see how they relate to each other.
Over the last few weeks I’ve been reworking and cleaning up the transactional file I/O in picotm’s libc component. It occures to me that while Unix systems dominate the operating-system landscape, many details of how they actually work are not widely documented1 and consequently not widely understood. With programmers coming from backgrounds other than C and Unix we now get to hear stories like this one.
In this blog post, we’ll look at what happens when an application opens and closes file descriptors on a Unix system. Whether it calls from C source code, Node.js, or any other Unix-like interface is not really important.
File Descriptors, Open File Descriptions, and Regular Files
On Unix systems, such as Linux, the BSDs, or MacOS, there are three major data structures that are relevant to file I/O. These are file descriptors, open file descriptions, and the file buffers themselves.
A call to open() takes the name of the file and the
file-access flags that describe whether the file should be opened for
reading or writing, etc. If a new file might be created, an optional third
argument specifies the new file buffer’s file mode.
Let’s look at an example by calling
int fd0 = open("/home/joe_user/my_file.txt", O_RDWR|O_CREAT, S_IRUSR|S_IWUSR|S_IRGRP);
We open the file buffer associated with the filename
/home/joe_user/my_file.txt for reading and writing (i.e., O_RDWR). If
no file buffer with this name exists, the kernel creates a new one (i.e.,
O_CREAT). The new file is readable by the process’ user and group, and
writable only by the process’ user (i.e., S_IRUSR|S_IWUSR|S_IRGRP).
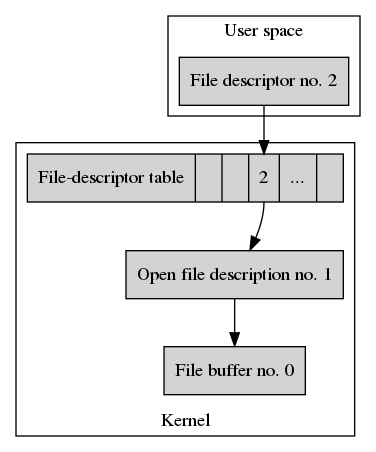
If we assume that a process has no files open yet, calling open() on
/home/joe_user/my_file.txt creates the following hierarchy of these data
stuctures.
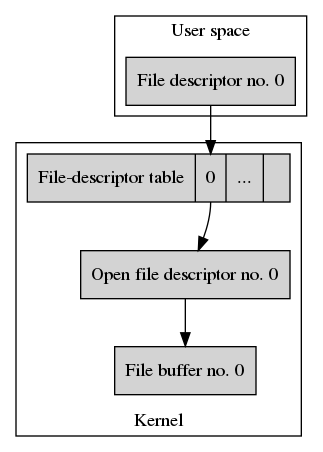
Let’s start with the file buffer. The file buffer is represented by File buffer no. 0 in our example. It’s the raw data stored in the regular file.
From now on we’ll also refer to file buffers as regular files. The term regular file is Unix-speak for a data buffer that is located on a file system and represented by a name in the file-system tree. The byte offset for reading from and writing to a regular file is freely choosable. Unix file I/O also knowns about multiple types of special files, directories, sockets, multiple types of memory objects, and more. A regular file is what we’d commonly expect to be a file.
Next, the kernel creates a new open file description, labeled Open file
description no. 0. in the example. The open file description stores all
state related to the opened file. That is the file-access flags supplied
with open() and the byte offset where the next read or write operation takes
place. In our example, the file-access mode is set to readable/writable and
the initial byte offset is 0. The open file description refers to the file
buffer we just retrieved from the file system.
The file buffer and the open file description are system-wide resources. Given the correct sequence of operations, multiple processes can get a hold on either of them and share their state.
To do so, each process maintains a so-called file-descriptor table. As the name suggests, it’s a table of all file descriptors of the process. A file descriptor is a process’ means of refering to an open file description. Each file descriptor refers to an open file description, which in turn refers to a file buffer.
The kernel always allocates the lowest available entry in the file-descriptor
table and associates it with the open file description it just created.
In the case of our invocation of open() this is entry 0.
Finally, open() returns the table index of the allocated file descriptor to
the process’s user-space application. Using the returned index, the application
can access the regular file via read() or
write(), etc. So if we now do
write(fd0, "Hello world!", strlen("Hello world!")); // write 12 byte
we write Hello world! to the beginning of File buffer no. 0 and increment the byte offset of Open file description no. 0 by 12 byte.
There’s a bit of confusing terminology here. When talking about the user-space integer value, one usually speaks of a file descriptor. But the actual file descriptor is in the process’ file-descriptor table in the kernel. The user-space value is just an index into this table.
Opening The Same File Multiple Times
Let’s open the file a second time.
int fd1 = open("/home/joe_user/my_file.txt", O_RDWR|O_CREAT, S_IRUSR|S_IWUSR|S_IRGRP);
Our hierarchy of data structures now looks like this.
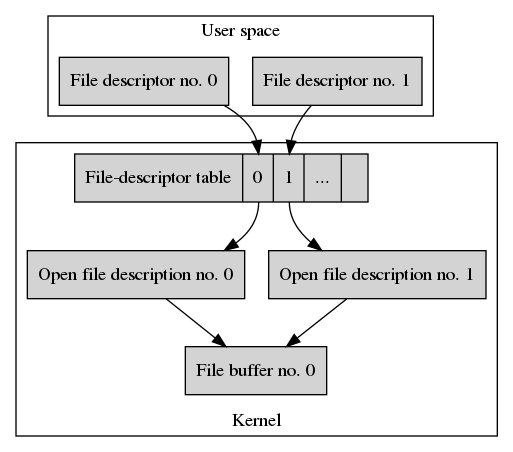
We already have a file buffer for the regular file with the name
of the user’s my_file.txt file. The Unix kernel uses this buffer for the
second call to open(). The O_CREAT flag is only relevant if the
regular file does not yet exist.
Every call to open() creates a new open file description. It’s labeled
Open file description no. 1 in our example. As before it’s initialized
with a byte offset of 0 and the file-access flags are taken from open().
For the new open file description, a new entry in the file-descriptor table is allocated and its index is returned to the user-space application. It’s called File descriptor no. 1 in our example.
Our application now has two file descriptors that refer to the same file
buffer, but these file descriptors don’t share any state besides the file
buffer’s content. So writing with fd1 starts at byte offset 0! Doing
write(fd1, "Salut monde!", strlen("Salut monde!"));
effectively overwrites the output we already wrote using fd0. The file
buffer now contains Salut monde! and the byte offset of
Open file description no. 1 is at position 12.
Duplicating File Descriptors
We can also have file descriptors that share their open file descriptions.
For this we use dup(). A call to dup() duplicates a file
descriptor, but reuses the open file description.
Let’s duplicate fd1.
int fd2 = dup(fd1);
This will setup our data structures as shown below.
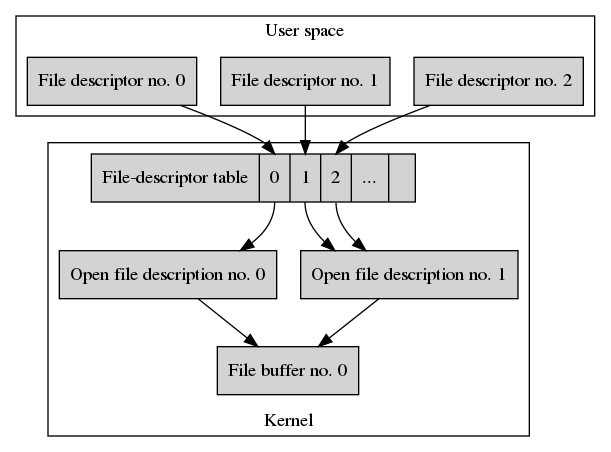
The call to dup() allocates a new entry in the process’ file-descriptor
table and copies File descriptor no. 1 to the new entry. The result is
the new File descriptor no. 2. Its table index is returned to the process’
user-space application.
In contrast to the previous example of opening a file twice, this time both file descriptors refer to the same open file description, which is Open file description no. 1.
Let’s write using both, fd1 and fd2.
write(fd2, " Ca", strlen(" Ca")); // write 3 byte
write(fd1, " va?", strlen(" va?")); // write another 4 byte
Both file descriptors share the same open file description, writing with
either therefore modifies the same byte offset. From the previous write
operation, the byte offset is already at position 12. We write another 3 byte
using ‘fd2’ and yet another 4 byte using fd1. Our file buffer now contains
the output Salut monde! Ca va? and the byte offset in Open file description
no. 1 is at position 19.
For a final exampleon writing, let’s again write using fd0.
File descriptor no. 0 refers to Open file description no. 0. Last time
we used it for writing Hello world! and the open file description’s byte
offset is still at position 12. That’s where the next write() operation
starts
write(fd0, " How's it going?", strlen(" How's it going?")); // write 16 byte
This command writes 16 byte at the offset of 12, effectively overwriting the previous output at this location. Our file buffer now contains the output Salut monde! How’s it going?.
Closing File Descriptors
Our process has created 3 file descriptors. Let us close fd1. Closing
is performed by calling close().
close(fd1);
Here’s how our hierarchy of data structures looks now.
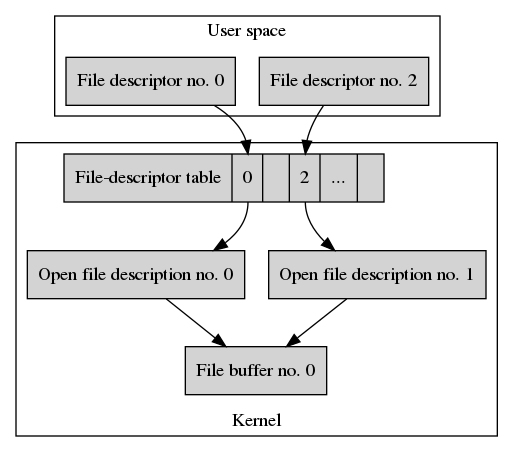
We can see that File descriptor no. 1 is not available to the application code any longer and the entry has been removed from the file-descriptor table.
We always close file descriptors, not open file descriptions or file buffers. Therefore the open file descriptions and the file buffer are still there! Each is still referenced and available for use with File descriptor no. 0 or File descriptor no. 2.
Now let’s close fd0 as well.
close(fd0);
As with the previous close operation, the file descriptor and the entry in the file-descriptor table are gone. And because no other file descriptor references Open file description no. 0, the kernel deletes this open file description and releases the memory. The file buffer File buffer no. 0 is still there, as it’s still referenced by Open file description no. 2.
If we would close the final file descriptor File descriptor no. 2 as well, the kernel would release all remaining data structures including File buffer no. 0.
Summary
This blog post describes the basic data structures of Unix file I/O.
- The content of regular files is stored in file buffers.
- Opening a regular file opens or creates the file’s file buffer.
- Each call to
open()creates a new open file description that stores the file-access flags and the byte offset for the next read or write operation. - Each open file description refers to a file buffer.
- Processes interact with open file descriptions and file buffers by using file descriptors.
- Each process contains its own table of file descriptors.
- File descriptors are duplicated using
dup(). - Duplicated file descriptors share the same open file description.
- File descriptors are closed using
close(). - The kernel releases the open file descriptions and file buffers automatically when they are not longer needed.
If you like this blog post about the basics of Unix File I/O, please subscribe to the RSS feed, follow on Twitter or share on social networks.
Maybe I turn this into a little series of blog posts. There’s interesting stuff happening during process forks; when using sockets; or in other interfaces that look like files, but aren’t.
Footnotes
-
There are a number of good books on Linux and Unix programming. If you’re interested in Linux system programming I’d recommend Michael Kerrisk’s The Linux Programming Interface. ↩